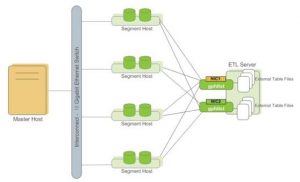
1 高可用方案
1.1 master高可用
master镜像是通过把primary master对应的standby master放置到不同的物理主机实现的。正常情况下只有primary master接受用户连接请求,standby master通过gpsyncagent进程(运行在standby master上)利用事务日志保持与primary master的同步。由于master上不存放任何用户数据,存放在其中的表不会频繁更新,因此同步是实时的。standby master所在主机除了复制进程外,没有正式master服务运行。当primary出现故障,standby master日志复制进程停止,可以手动激活standby master,使它切换成primary master。需要在primary与standby之上再加一层负载均衡或者VIP,应用在master切换后才可以不修改连接配置继续访问数据库。

1.2 segment高可用

segment级别的镜像是通过把primary segment对应的mirror segment放置到不同的物理主机实现的。正常情况下,只有primary segment的instance处于工作状态,所有primary segment上的变化通过文件块的复制技术拷贝到mirror segment。因此,存放mirror segment的主机上只有复制用的进程,而不存在mirror segment instance。一旦primary segment出现故障,mirror segment的复制进程停止,并启动instance,保证数据库的操作继续。
segment的故障检测是通过后台进程ftsprobe实现的,并可以进行自动容错,不需要DBA进行干预。ftsprobe的检测间隔是通过global服务参数gp_fts_probe_interval进行定义的,默认值是1分钟,通常这个参数的设置应该与参数gp_segment_connect_timeout保持一致。一旦ftsprobe进程发现primary segment出现故障,它会在数据字典中标记该segment已经停止。只有管理员对其进行恢复后,才会改变状态。
如果系统没有进行segment级别的镜像,当出现segment故障后,整个系统都将脱机,直到恢复故障segment后,才可以重新启动。
2 高可用搭建及测试
2.1 master高可用搭建
2.1.1 创建standby
1、在master上执行:
gpinitstandby -s lzk-8 -P 2345
2、并在终端中设置standby的数据目录:
Enter standby filespace location for filespace pg_system (default: NA):
> /data0/master_standby/gpseg-1
如出现如下提示,则表示创建成功
gpinitstandby:lzk-8:greenplum-[INFO]:-Successfully created standby master on lzk-8
2.1.2 手动切换
- 单独停止master
在master上执行:
gpstop -m
- 启动standby
在standby上执行
gpactivatestandby -d $MASTER_DATA_DIRECTORY
2.1.3 master崩溃测试
- 模拟master崩溃
在master上
kill -9 所有master进程
此时活跃的客户端连接被断开,segments上正在执行的进程并不会停止,继续执行。standby不会自动进行切换,无法连接GPDB服务。
- 启动standby
在standby上执行:
gpactivatestandby -d $MASTER_DATA_DIRECTORY
启动后,可以在新的端口及IP上接受新的连接。segments上遗留的进程执行完后不会进行提交,而是回滚。
2.1.4 测试结论
- 在master崩溃时尚未提交的所有事物都会失败。
- Greenplum本身并不会监控master的健康状态及异常恢复。所以集群恢复服务时间取决于发现异常后手动启动standby的时间。
2.2 segment高可用搭建
2.2.1 创建mirrors
1、在master上执行
gpaddmirrors -o mirror_config
会生成一个参考的配置文件,可自行修改
$ cat mirror_config
filespaceOrder=
mirror0=0:lzk-8:56000:57000:58000:/data0/mirror/gpseg0
mirror1=1:lzk-8:56001:57001:58001:/data0/mirror/gpseg1
2、创建mirror,执行:
gpaddmirrors -i mirror_config
如出现如下提示,则表示创建成功:
gpssd-[INFO]:-Mirror segments have been added; data synchronization is in progress.
gpssd-[INFO]:-Data synchronization will continue in the background.
gpssd-[INFO]:-
gpssd-[INFO]:-Use gpstate -s to check the resynchronization progress.
可以使用gpstate -s查看同步进度
2.2.2 segment崩溃测试
- 模拟segment崩溃
在一个segment上
kill -9 所有segment进程
此时正在执行的sql语句会报错失败,但是连接正常,可以继续使用。同时其他正常segment上正在执行的进程也会退出。异常segment对应的mirror会自动接管,并转为primary。使用gpstate可以看到warning:
[WARNING]:-Total primary segment failures (at master) = 1
如当前正在执行的sql语句并没有涉及到全部segment,则不涉及到的segment崩溃不会导致当前sql失败。
- 修复异常的primary segment
执行gprecoverseg
此时异常的primary以mirror身份加入集群,并同步最新的segment数据。primary与mirror身份目前是互换的,如果采用机器间互相备份的方式会影响性能。所以正常后需要恢复原来的身份。
恢复节点原来的身份:
执行gprecoverseg -r
2.2.3 测试结论
- segment崩溃时正在运行的事物会全部失败。
- mirror会自动接管服务而无需人工干预,接管过程中会有几秒的不可用时间;执行gprecoverseg操作时会有不可用时间,表现为语句执行卡顿;执行gprecoverseg -r操作时需要重启segment,所以也会有不可用时间,表现为语句执行报错。
3 集群扩容
3.1 创建新增segment
- 将新加入的host写入hostfile文件中
- 自动生成扩容配置文件
gpexpand -f ./etc/hostfile -D lzk,并输入需要增加的节点数及data目录
成功会生成类似配置文件:gpexpand_inputfile_20171211_153009
- 看一下配置文件内容,可根据需要手动调整:cat gpexpand_inputfile_20171211_153009
lzk-8:lzk-8:50002:/data3/data2/gpseg2:4:2:p
lzk-8:lzk-8:50003:/data4/data2/gpseg3:5:3:p
- 初始化新的segment
gpexpand -i gpexpand_inputfile_20171211_153009 -D lzk
3.2 数据重分布
- 可以查询gpexpand中的数据表来查看需要重分布的表及优先级
- 执行重分布命令,-d表示启动重分布命令后持续执行的时间
gpexpand -d 01:00:00 -D lzk
- 全部完成后清除重分布使用的schema:gpexpand
gpexpand -c -D lzk
3.3 测试结论
重分布过程中严重影响数据库性能,故需必须要在业务闲时进行,如数据量非常大可以通过-d命令控制执行的时间段。集群只能扩容不能进行缩容,如一定要缩容需要进行数据导出、导入。