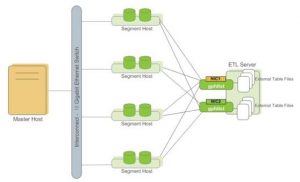
1 GP表设计
1.1 分布键
GP作为一个MPP数据库,分布键的选择对于后期使用的性能影响非常大。即使GP运行在单机环境,GP数据也是存放在多个segment上,所以必须要选择合适的分布键,特别是从单机数据库迁移到GP上的业务,因为单机数据库 不涉及分布键,所以迁移之前一定要设计好所有表的分布键。每张表必须显式指定分布键,避免使用默认分布。
- 尽可能的避免各个节点之间的数据交互以提高性能。两表关联查询时如果关联字段包含分布键,则数据可以在各自节点内完成运算;如果关联字段不包含分布键,则需要进行数据重分布,产生大量网络、内存开销,性能很低。
- 尽可能选择能使数据均匀分布在各个节点的分布键。如果数据分布不均匀,性能瓶颈就会出现在数据最多的节点上,导致其他节点很空闲,而都在等待该节点执行完成,造成性能低及资源浪费。
例如人员主题库类的业务,表之间查询、关联都是以人员为单位,而区分人员则使用的是身份ID。并且身份ID 散列度非常高,可以保证数据均匀分布。所以这类业务里的绝大多数表都非常适合使用身份ID字段作为分布键。
可以通过select gp_segment_id,count(*) from table_name group by gp_segment_id检查表数据是否均匀分发到每个segment上。
1.2 表分区
GP只支持range、list两种分区,不支持hash分区。GP使用表继承方式实现分区表,实际上每个分区都是一张单独的表,并且对于列存类型的表,每一列都需要一个单独的文件,每台服务器上的文件数=segment数*表数量*表分区数量*列数,所以为了避免文件系统上文件过多,仅对大表进行分区。
按照某个字段进行分区不会影响数据在节点上的分布,但是合理的选择分区字段可以让查询只扫描需要访问的分区,加快在单个数据节点的查询速度。
例1:
某张明细数据类的表,每天都有明细数据,经常按天查询明细数据,且数据保留N个月。则适合使用业务日期作为表分区键。按天查询数据可以只访问需要查询的分区,不会全表查询。删除过期数据时可以直接删除过期分区。
例2:
某张人员基本信息类的表,业务经常需要按省份进行统计各项指标。则适合使用省级代码作为表分区键。需要更新某省份数据时可以清空该省份分区后导入。并且统计时绝大多数操作都可以在分区内完成。
1.3 表存储方式
行存储是一行的所有列在磁盘上连续存储,所以一次IO可以从磁盘上读取整个行的数据。
列存储是在磁盘上将同一列的只保存在一起。
GP同时支持行存及列存。行列存储的特点和对比网上有很多文章可以参考,这里只列举一下各自适用的场景:
适合使用行存的场景:
- 数据经常需要修改
- 每次查询的字段占表全部列的大部分
适合使用列存的场景:
- 数据不需要修改或极少修改
- 表字段数多且经常查询其中少量字段
- 表数据量很大,需要压缩来提高IO性能
1.4 索引
GP则是通过索引设计提高数据检索性能 。
- 对于经常需要根据条件检索少量数据的高基数列建立索引
- 对于经常用于表关联的字段建立索引
- 频繁更新的列不要建立索引
- GP索引对数据加载性能影响很大,所以在加载大量数据前可以先删除索引,加载结束后重建索引
2 最佳实践
2.1 ANALYZE
ANALYZE用于收集表的统计信息,以优化执行计划。
如果使用INSERT、UPDATE、DELETE操作或修改大量数据之后,或导入数据后,建议执行ANALYZE。
创建新的索引之后也建议执行ANALYZE。
2.2 VACUUM
VACUUM用于回收表空间并可以再次使用,不会申请排他锁,其他会话仍可以正常读写该表。如果加上FULL参数,则会请排他锁,阻塞其他操作。
所以建议对于经常修改或删除的表,定期在闲时执行VACUUM操作,释放空间。不建议使用VACUUM FULL,可以使用create table … as操作,然后删除原表重命名新表。
2.3 加载数据
GP支持COPY方式入库和外部表方式入库。COPY方式所有数据会经过MASTER节点,由MASTER进行分发,性能较低,但是使用方便,对于少量数据可以使用COPY方式入库。外部表方式所有的segment节点都会并行加载数据,需要开启gpfdist服务并创建外部表,但是性能较高,对于大量数据建议使用外部表方式入库。
2.4 执行计划
GP采用基于成本的优化器来评估执行查询的不同策略,并选择成本最低的方法。和其他关系数据库系统的优化器相似,在计算不同执行计划的成本时,GP的优化器会考虑诸如关联表的行数、是否有索引、字段数据的基数等因素。还会考虑到数据的位置,尽可能在segment上完成任务,降低在不同segments间传输的数据量。
在一个查询运行速度比预期慢时,可以查看优选器生成的执行计划以及执行每一步的代价。这有助于确定哪一步最耗资源,进而可以修改查询或者模式,以便生成更好的计划。查看查询计划使用 EXPLAIN 语句。
执行详细描述了GP执行查询的步骤。查询计划是颗节点树,从下向上阅读,每个节点将它的执行结果数据传递给其上的节点。每个节点表示查询计划的一个步骤,每个节点都有一行信息描述了该步骤执行的操作,例如扫描、关联、聚合或者排序操作等,此外还有显示执行该操作的具体方法。例如,扫描操作可能是顺序扫描或者索引扫描,关联操作可能是哈希关联或者嵌套循环关联。
例:
postgres=# explain select datasetid,count(*) from t1 group by datasetid;
QUERY PLAN
———————————————————————————————————————–
Gather Motion 8:1 (slice2; segments: 8) (cost=8272479.90..8272484.15 rows=340 width=90)
-> HashAggregate (cost=8272479.90..8272484.15 rows=43 width=90)
Group By: t1.datasetid
-> Redistribute Motion 8:8 (slice1; segments: 8) (cost=8272468.00..8272474.80 rows=43 width=90)
Hash Key: t1.datasetid
-> HashAggregate (cost=8272468.00..8272468.00 rows=43 width=90)
Group By: t1.datasetid
-> Append-only Columnar Scan on t1 (cost=0.00..6662468.00 rows=40250000 width=33)
Optimizer status: legacy query optimizer
(9 rows)
可以从上面执行计划看到会依次执行:
- Append-only Columnar Scan
- HashAggregate
- Redistribute Motion
- HashAggregate
- Gather Motion。
即:
- 在8个segments上对Append-only表进行列扫描
- 因为有汇聚函数,进行hash汇聚
- 未使用表分布键进行汇聚,所以需要进行数据重分布
- 重分布后进行hash汇聚
- master收集各节点结果并返回结果集
分析执行计划时首先要找估算代价较高的步骤。对比估算的行数及代价与操作实际需要处理的行数,以判断是否合理。
如果有分区表,判断分区裁剪是否有效。分区裁剪需要查询条件(WHERE 子句)必须和分区条件一样,不能包含子查询。
如果执行计划顺序不是最优的,检查数据库统计信息是否最新的。这时就要运行ANALYZE,生成最优计划。
注意计算倾斜。当执行诸如哈希聚合和哈希关联等操作符时,若不同Segment执行代价分布不均,就会发生计算倾斜。由于某些Segment比其他Segment使用更多的CPU和内存,性能下降明显。原因可能是关联、排序、聚合字段基数低或者数据分布不均匀。通过EXPLAIN ANALYZE 可以检测计算倾斜。每个节点都含有Segment处理的最多行数和所有Segment的平均行数。如果最大行数比均值大很多,那么至少有一个Segment需要处理更多的工作,因而有计算倾斜的可能性。
例:
postgres=# explain analyze select c1,count(*) from t1 group by c1;
QUERY PLAN
——————————————————————————————————————————————————
Gather Motion 8:1 (slice1; segments: 8) (cost=10821491.42..15184888.40 rows=145149885 width=90)
Rows out: 311959999 rows at destination with 44285 ms to first row, 125533 ms to end, start offset by 42 ms.
-> HashAggregate (cost=10821491.42..15184888.40 rows=18143736 width=90)
Group By: c1
Rows out: Avg 38994999.9 rows x 8 workers. Max 39002895 rows (seg2) with 46671 ms to first row, 75735 ms to end, start offset by 44 ms.
Executor memory: 131464K bytes avg, 131464K bytes max (seg0).
Work_mem used: 127901K bytes avg, 127901K bytes max (seg0). Workfile: (8 spilling, 0 reused)
Work_mem wanted: 3020300K bytes avg, 3020885K bytes max (seg2) to lessen workfile I/O affecting 8 workers.
(seg2) 39002895 groups total in 32 batches; 1 overflows; 40032573 spill groups.
(seg2) Hash chain length 4.7 avg, 19 max, using 8568049 of 8650752 buckets.
-> Append-only Columnar Scan on t1 (cost=0.00..6662468.00 rows=40250000 width=26)
Rows out: Avg 40250000.0 rows x 8 workers. Max 40257783 rows (seg2) with 80 ms to first row, 10405 ms to end, start offset by 46 ms.
Slice statistics:
(slice0) Executor memory: 413K bytes.
(slice1) * Executor memory: 131822K bytes avg x 8 workers, 131822K bytes max (seg0). Work_mem: 127901K bytes max, 3020885K bytes wanted.
Statement statistics:
Memory used: 128000K bytes
Memory wanted: 3021084K bytes
Optimizer status: legacy query optimizer
Total runtime: 144500.021 ms
(20 rows)
可以看出上面的执行计划在各个阶段内存和IO对比中max与avg差别都很小,说明数据分布很好,没有倾斜。