1 数据类型对比
| MySQL | PostgreSQL | comments | |
| 数值类型 | TINYINT | SMALLINT | gp中无zerofill属性及unsigned类型,所以为了数据不越界需使用大一精度的数据类型匹配 |
| SMALLINT | SMALLINT | ||
| MEDIUMINT | INTEGER | ||
| INT|INTEGER | INTEGER | ||
| BIGINT | BIGINT | ||
| TINYINT UNSIGNED | SMALLINT | ||
| SMALLINT UNSIGNED | INTEGER | ||
| MEDIUMINT UNSIGNED | INTEGER | ||
| INT UNSIGNED | BIGINT | ||
| BIGINT UNSIGNED | NUMERIC(20) | ||
| BIT | BIT | ||
| FLOAT | REAL | ||
| FLOAT UNSIGNED | DOUBLE PRECISION | ||
| DOUBLE|REAL|DOUBLE PRECISION | DOUBLE PRECISION | ||
| DECIMAL|DEC|NUMERIC|FIXED | NUMERIC | ||
| 字符类型 | CHAR | CHARACTER|CHAR | |
| VARCHAR | CHARACTER VARYING|VARCHAR | ||
| TINYTEXT | TEXT | ||
| TEXT | TEXT | ||
| MEDIUMTEXT | TEXT | ||
| LONGTEXT | TEXT | ||
| BINARY|CHAR BYTE | BYTEA | ||
| VARBINARY | BYTEA | ||
| TINYBLOB | BYTEA | ||
| BLOB | BYTEA | ||
| MEDIUMBLOB | BYTEA | ||
| LONGBLOB | BYTEA | ||
| 时间类型 | DATE | DATE | |
| TIME | TIME | ||
| YEAR | 无 | ||
| DATETIME | TIMESTAMP | ||
| TIMESTAMP | TIMESTAMP | ||
| 其他类型 | BOOL|BOOLEAN | BOOLEAN | |
| ENUM | CREATE TYPE … AS ENUM | ||
| SET | 无 |
2 语法对比
2.1 limit
MySQL:
|
1 |
LIMIT offset, limit |
or
|
1 |
LIMIT limit OFFSET offset |
Greenplum:
|
1 |
LIMIT limit OFFSET offset |
2.2 replace
MySQL:
|
1 2 3 |
REPLACE [INTO] tbl_name [(col_name,...)] {VALUES | VALUE} ({expr | DEFAULT},...),(...),... |
Greenplum:
不支持该语法,需要使用函数实现,例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE FUNCTION replace() RETURNS void AS $$ BEGIN IF EXISTS( SELECT * FROM phonebook WHERE name = 'john doe' ) THEN UPDATE phonebook SET extension = '1234' WHERE name = 'john doe'; ELSE INSERT INTO phonebook VALUES( 'john doe', '1234' ); END IF; RETURN; END; $$ LANGUAGE plpgsql; |
2.3 insert into … on duplicate key update
MySQL:
|
1 2 3 4 5 6 7 8 9 |
INSERT [INTO] tbl_name [(col_name,...)] {VALUES | VALUE} ({expr | DEFAULT},...),(...),... [ ON DUPLICATE KEY UPDATE col_name=expr [, col_name=expr] ... ] |
Greenplum:
不支持该语法,需要使用函数实现,例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE FUNCTION replace() RETURNS void AS $$ BEGIN IF EXISTS( SELECT * FROM phonebook WHERE name = 'john doe' ) THEN UPDATE phonebook SET extension = '1234' WHERE name = 'john doe'; ELSE INSERT INTO phonebook VALUES( 'john doe', '1234' ); END IF; RETURN; END; $$ LANGUAGE plpgsql; |
2.4 select … into outfile
MySQL:
|
1 2 3 |
SELECT ... INTO OUTFILE 'path/file_name' |
Greenplum:
|
1 2 3 |
COPY ( SELECT ... ) TO 'path/file_name' |
2.5 自增列
MySQL:
列加auto_increment属性,例:create table a(id int auto_increment primary key)
获取当前值:select last_insert_id()
Greenplum:
字段类型使用serial,例:create table a(id serial primary key)
获取当前值:select currval(‘a_id_seq’)
2.6 注释
MySQL:
使用#或–
Greenplum:
使用–
2.7 执行存储过程
MySQL:
|
1 |
call proc_name() |
Greenplum:
Greenplum并无存储过程,使用函数代替,所以执行:
|
1 |
select proc_name() |
3 常用函数对比
3.1 时间函数
3.1.1 时间转字符串
MySQL:date_format()
例:select date_format(now(),’%Y%m%d%H%i%s’)
Greenplum:to_char()
例:select to_char(now(), ‘YYYYMMDDHH24MISS’)
3.1.2 字符串转时间
MySQL:str_to_date()
例:select str_to_date(‘20171120′,’%Y%m%d%H%i%s’)
Greenplum:to_date(),to_timestamp()
例:select to_date(‘20171120’, ‘YYYYMMDD’)
select to_date(‘20171120’, ‘YYYYMMDDHH24MISS’)
3.1.3 时间计算
MySQL:date_add()
例:select date_add(now(), interval 2 day)
Greenplum:直接计算
例:select now() + interval ‘2 day’
3.2 字符函数
3.2.1 空字符串处理
MySQL:ifnull
例:select ifnull(null,‘default’)
Greenplum:coalesce
例:select coalesce(null,‘default’)
3.2.2 字符串拼接
MySQL:concat()
例:select concat(‘abc’,‘def’)
Greenplum:||
例:select ‘abc’||’def’
4 数据迁移
Greenplum数据导入3种方式:
4.1 COPY命令
COPY需要经过master,仅建议在小数据量时使用。无法并行导入,在大量数据导入时效率很低,不过多介绍。
例:COPY tablea FROM ‘/data/tablea_data’;
4.2 使用外部表
外部表以及4.3中的gpload都需要使用gpfdist服务。
gpfdist是Greenplum自带的一个并行文件服务,原理如下图:
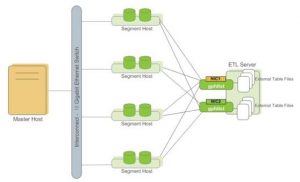
gpfdist为每个segment提供并行读写数据文件的服务。
1、先启动gpfdist服务,例:
|
1 |
gpfdist -d /data0/data -p 8123 -l /home/greenplum/gpfdist.log & |
-d 指定数据目录 -p指定服务端口 -l 指定日志文件
将数据文件放入该目录下
2、创建外部表,例:
|
1 |
create external table lzk.a(a int,b varchar(50)) location (‘gpfdist:localhost:8123/a.txt’) fromat ‘text’(delimiter ‘,’) |
- 从外部表导入数据,例:
|
1 |
create table t as select * from a; |
或者先创建,后导入:
|
1 2 3 |
create table t (a int,b varchar(50)) distributed by (a); insert into t select * from a; |
4.3 gpload
通过配置yaml控制文件来进行数据导入,同样依赖gpfdist服务。
例:
1、编辑a.yml文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
VERSION: 1.0.0.1 DATABASE: lzk USER: greenplum HOST: localhost PORT: 5432 GPLOAD: INPUT: - SOURCE: LOCAL_HOSTNAME: - localhost PORT: 8234 FILE: - /data0/data/a.txt - COLUMNS: - a: integer - b: text - FORMAT: text - DELIMITER: ',' - ERROR_LIMIT: 25 - LOG_ERRORS: true OUTPUT: - TABLE: public.a - MODE: INSERT |
2、进行导入:
|
1 |
gpload -f a.yml -l a.log |